Assessing AI-Generated Data Quality
A primer on precision versus recall
The quantity of data generated by machines over the last decade has been staggering. However, in order to determine how data can be incorporated into business processes and used to inform decision making, it is critical to thoroughly understand the quality of that data. But how can you judge quality, especially when a dataset comes from a complex algorithm or AI model?
Data quality has many facets. It’s often defined as accuracy; in short, does the data reflect the real world? Subsets of accuracy include questions around the completeness of data and inconsistencies within the data. A second factor is around the predictiveness of data. Does the data tell us something about potential outcomes?
In this series, we will introduce concepts and ideas that will help businesses judge the accuracy, predictiveness, consistency, and timeliness of AI-generated data sources, and how each of these can affect the ability to make decisions.
Let’s begin with accuracy. Whether data is generated by man or by machine, there will be errors in any large dataset. Realistically, no data source is perfectly correct. Whether data is being used in insurance, healthcare, or elsewhere, the distribution and prevalence of errors should be taken into account. If errors can be characterized and understood, a dataset can be used optimally for decision-making purposes because errors are no longer seen as randomized across the dataset. In looking at errors, it’s important to consider that there are two different kinds: Type I (false positives) and Type II (false negatives).
Below is a simplified example showing how false positives and negatives would present themselves for an AI model that is pinpointing homes with bad-quality roofs (where roofs are either classified as good or as bad).
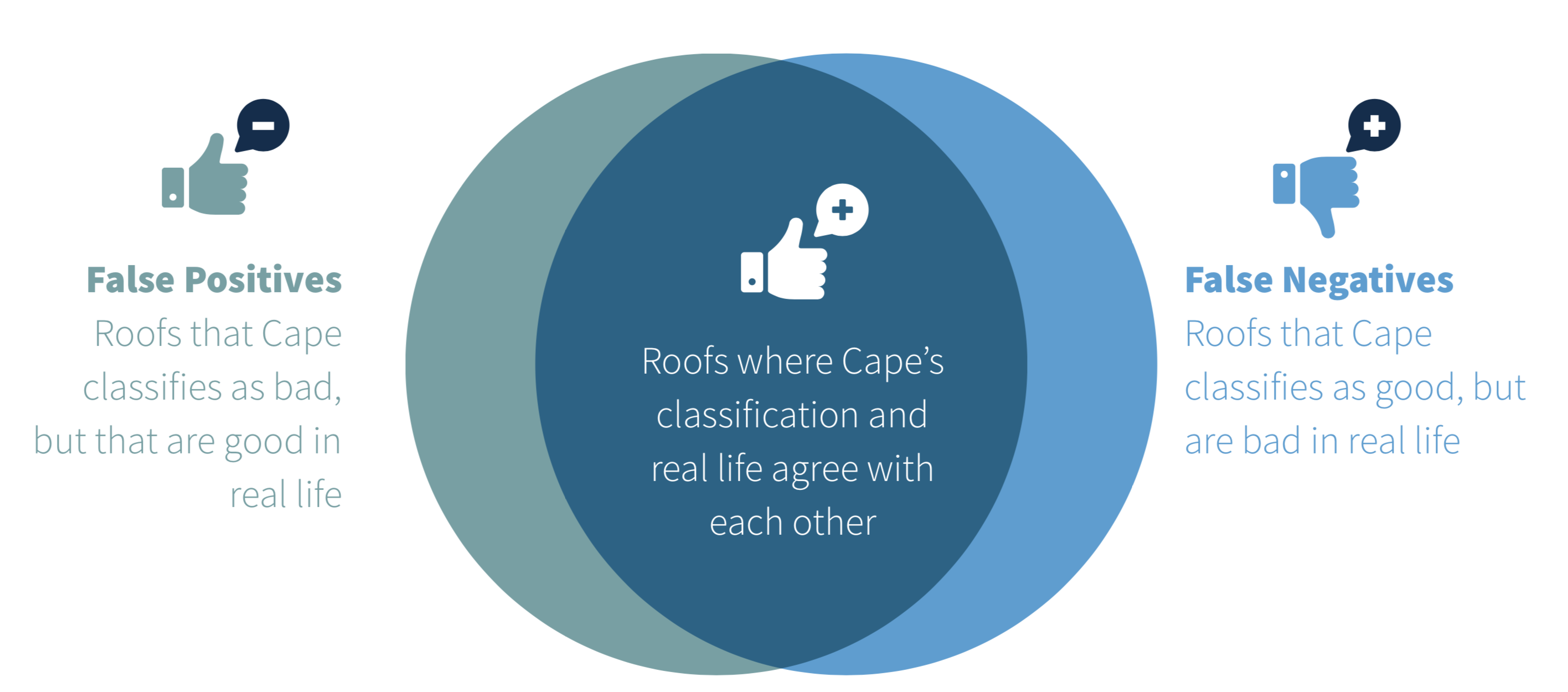
In fact, false positives and negatives are part of a larger conceptual framework that is at the foundation of machine learning. This framework, known as a confusion matrix, is shown below:
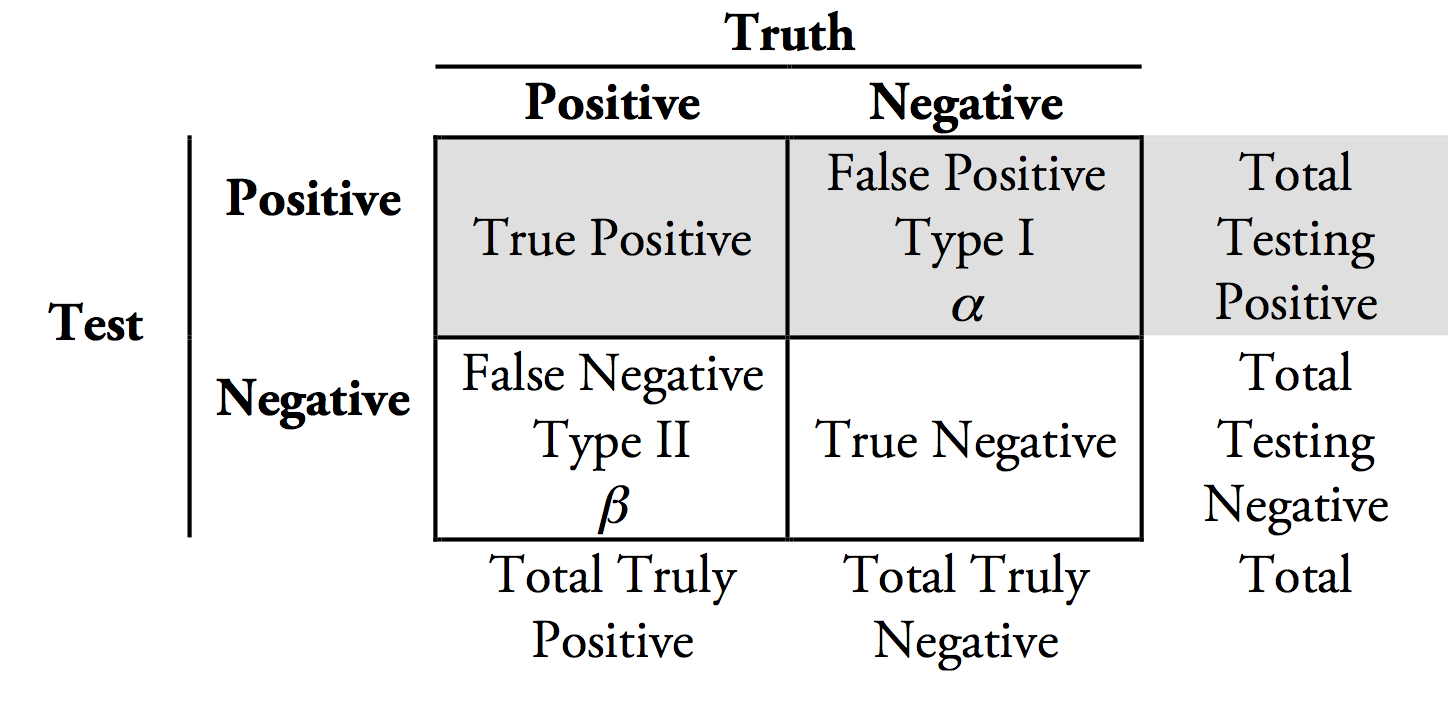
Typically, model output is a tradeoff between false positives and false negatives, and learning models can be optimized to either minimize one or the other. The two kinds of errors within a dataset can have different impacts when integrated into business decision making. So by optimizing a model and relegating most errors to a single type, users can have more confidence in the model results and will know what potential issues to look for. To understand how this is done, we need to take a step deeper into the concepts of precision and recall.
Precision describes the purity of model output: the percentage of positive results that are correct. A model focusing on precision minimizes false positives.
Recall, on the other hand, describes the completeness of model output: the percentage of all possible positive results that are correctly returned by the model. A model focusing on recall minimizes false negatives.
It’s easier to understand these concepts when used in an example.
Let’s say there is a doctor who is interpreting 100 blood tests and deciding whether or not a disease is present. In this case, the presence of disease is a positive result, and no disease is a negative result. If the doctor analyzes the tests and identifies a disease 40 times but was only correct 30 of those times, then her precision would be 75% (30 / 40 * 100). 10 of those cases would be false positives, where the patient would be diagnosed with a disease even though they are healthy. If there were 50 total cases of disease out of the 100 tests, and she diagnosed 30 of them correctly, her recall would be 60% (30 / 50 * 100). 20 patients receive a false negative diagnosis: they have the disease but were told they are healthy.
Here, we can clearly see the different costs of being wrong in either direction. In this setting, it’s critical to have high recall, so people with a disease have the highest chance of receiving helpful treatment, even if this comes at the expense of some healthy people being misdiagnosed.
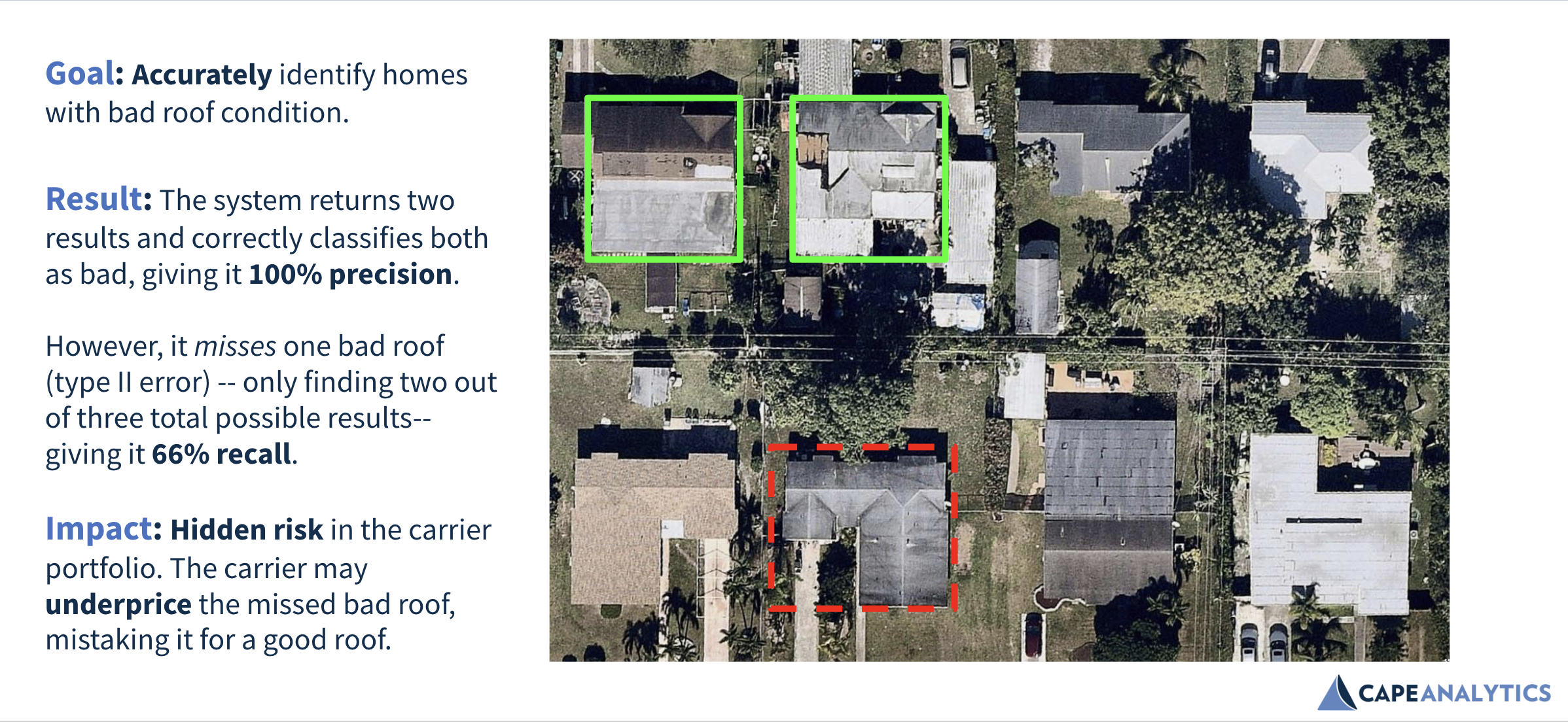
Let’s apply precision and recall to an insurance use case. Below is the result of a machine learning model tuned for precision, where the insurer wants Cape to minimize the chances of being wrong when identifying bad roof condition (assessing accuracy).
Next is an example of a model tuned for recall, where a user wants to minimize the chances of missing a bad roof across the entire data set (assessing completeness).
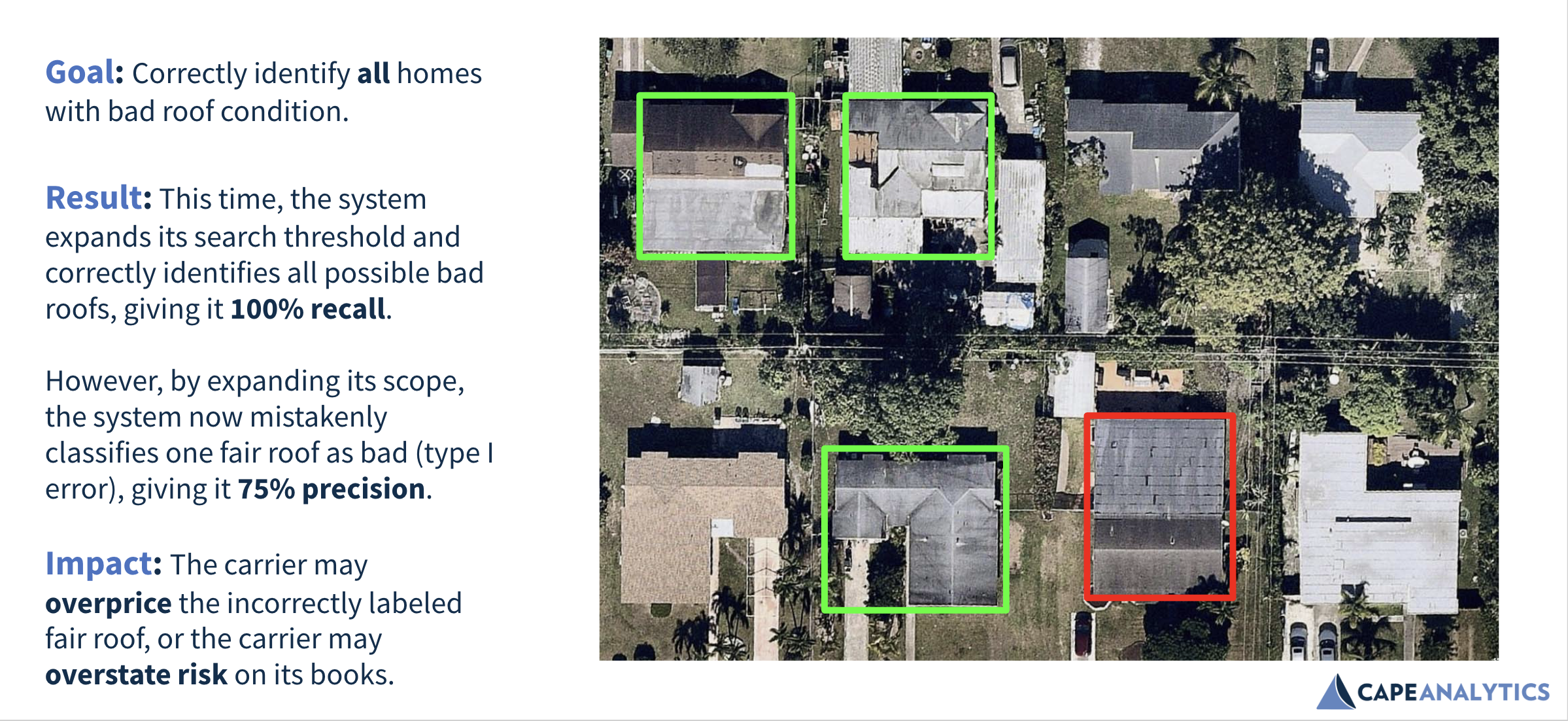
This example shows the tradeoff between minimizing false positives (precision) and minimizing false negatives (recall), and how one may be better for some use cases and worse for others. If a user knows the direction a dataset is most likely to be wrong, they can select a use case where the cost of being wrong in that direction is lower than the cost of being wrong in the other direction.
For example, at Cape, we’ve designed our Roof Condition Rating model with high recall and recommend that carriers use the model to filter large policy portfolios down to a small number of potentially bad risks that their underwriters should review. In this use case, we want to avoid letting bad risks “slip through the cracks,” as the cost of a severe quality roof being priced as a good quality roof can lead to greater-than-expected losses in the future.
On the other hand, an insurance carrier would want high precision when automating critical business decisions, such as declining a customer at the time of application, based on data alone and without any kind of human review. In this case, an insurer needs precision, in order to minimize the chance that a good risk would be incorrectly categorized as bad, and a good potential customer lost in the process.
The ability to improve model precision or recall can have large downstream effects on data usefulness over time. At Cape Analytics, we’re constantly evolving our models to improve both precision and recall, and providing our customers with additional metadata that can be used for tailored implementations. In 2018 alone, we improved the precision of our loss-predictive Roof Condition Rating attribute by 30 percent, minimizing false positives across the board. This continual improvement gives our clients the confidence to know they are working with the very best data available on the market today.
The confusion matrix, false positives and negatives, precision versus recall — these concepts help us understand how to measure data accuracy. Still, as noted in the introduction, accuracy is only one part of the equation. Another major factor is the predictiveness of data. Does the data provide some signal that can help us predict future customer behavior or outcomes?